Jak działa system plików Ext2?
Wstęp
Systemy plików z rodziny Ext to najczęściej wykorzystywane systemy plików we wszelakich Linuksach. W tym artykule opiszę zasadę działania systemu plików Ext2 pokazując jak realizowane są w nim operacje odczytu plików.
Dlaczego skupiam się na Ext2 a nie Ext4? Otóż dlatego, że Ext4 stanowi rozwinięcie Ext2 o mechanizm księgowania (dodany w Ext3), większe limity rozmiarów plików czy dokładniejsze przechowywanie daty utworzenia pliku. Podstawy działania tych systemów są jednak identyczne.
Struktura partycji Ext
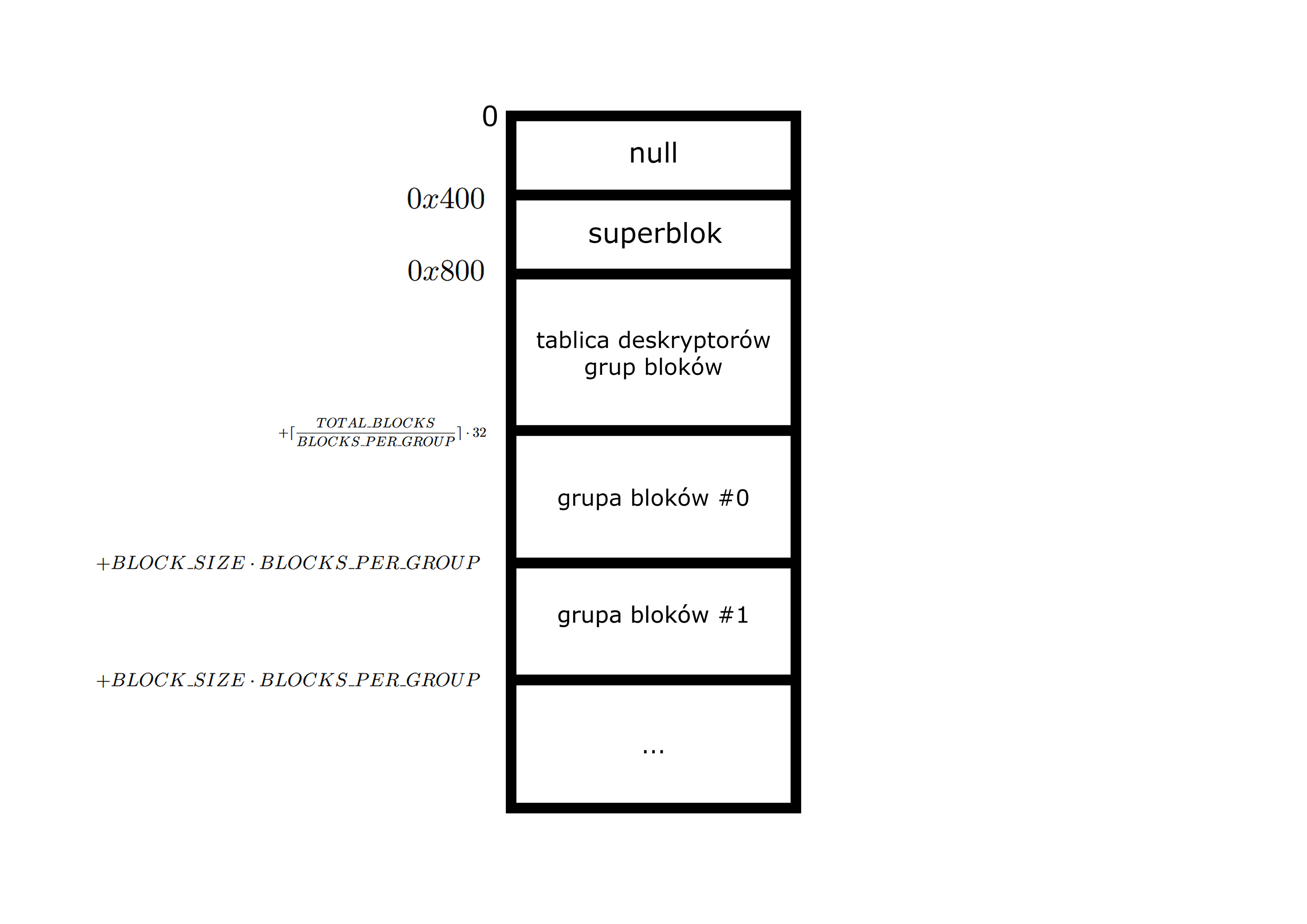
Partycja Ext2 składa się z:
- pustego 1KB
- Superbloku (począwszy od offsetu 0x400) - zawierającego podstawowe informacje o systemie plików
- tablicy deskryptora grup bloków (począwszy od offsetu 0x800)
- grupy bloków w których skład wchodzą bloki zawierające:
- mapy bitowe użycia i-węzłów i bloków
- tablice i-węzłów
- dane plików
- mogą także zawierać redundantne kopie superbloku czy tablicy deskryptorów grup bloków
Superblok
Superblok zawiera najpotrzebniejsze informacje odnośnie systemu plików. Choć nie ma potrzeby pamiętać całej jego struktury na pamięć, warto mieć z tyłu głowy nastepujące pola, gdyż przydadzą się w dalszej części tego wpisu:
- log2_block_size -> block_size = 1024 « log2_block_size
- blocks_per_group
- inodes_per_group
struct superblock_t { uint32_t total_inodes; uint32_t total_blocks; uint32_t root_reserved_blocks; uint32_t total_unallocated_blocks; uint32_t total_unallocated_inodes; uint32_t block_no_of_superblock; uint32_t log2_block_size; uint32_t log2_fragment_size; uint32_t blocks_per_group; uint32_t fragments_per_group; uint32_t inodes_per_group; uint32_t last_mount_time; uint32_t last_write_time; uint16_t mounts_since_last_fsck; uint16_t fsck_frequency; // In mount times uint16_t signature = 0xEF53; uint16_t fs_state; uint16_t error_handling; uint16_t version_minor; uint32_t last_fsck_time; uint32_t os_id; uint32_t version_major; uint16_t user_id_reserved; uint16_t group_id_reserved; } // Opcjonalnie istnieją też "rozszerzone" pola superbloku, które z premedytacją pominąłem
Tablica deskryptorów grup bloków (Block Group Descriptor Table)
Tablica deskryptorów grup bloków zawiera informacje odnośnie poszczególnej grupy bloków, z perspektywy dalszej części wpisu istotne jest pole inode_table_ptr które wskazuje, gdzie znajduje się tablica i-węzłów wewnątrz opisywanej grupy.
struct bgd_t {
uint32_t block_usage_bitmap_ptr;
uint32_t inode_usage_bitmap_ptr;
uint32_t inode_table_ptr;
uint16_t unallocated_blocks;
uint16_t unallocated_inodes;
uint16_t directories_count;
uint8_t unused[14];
}
Sposób przechowywania plików
O pliku powinniśmy myśleć jako o surowym ciągu bajtów (np. znaków ASCII w przypadku plików tekstowych). Pozostałe informacje o pliku takie jak jego nazwa, rozmiar, uprawnienia czy typ to metadane o pliku. W systemach plików Ext metadane o pliku rozrzucone są w 2 miejsca:
- Katalog nadrzędny zawiera informacje nt. nazwy, typu i numer i-węzła opisującego ten plik
- i-węzeł zawiera m.in. typ, uprawnienia, rozmiar i najważniejsze: adresy bloków z danymi (treścią) tego pliku
Czym jest katalog?
Intuicyjnie katalog możemy nazwać “zbiorem plików” i jest to całkiem trafna definicja. W systemach plików Ext katalog jest plikiem, którego treścią jest lista plików zawartych w tym folderze.
Choć poniżej przedstawiam całą strukturę wpisu w takiej liście, najważniejszą informacją na ten moment to fakt, że przechowywana jest nazwa oraz i-węzeł opisujący konkretny plik.
struct dir_entry_t {
uint32_t inode_n; // Numer i-węzła opisującego plik
uint16_t entry_size; // Rozmiar wpisu wewnątrz listy
uint8_t file_name_size;
uint8_t type_indicator;
char file_name[file_name_size];
}
Czym jest i-węzeł?
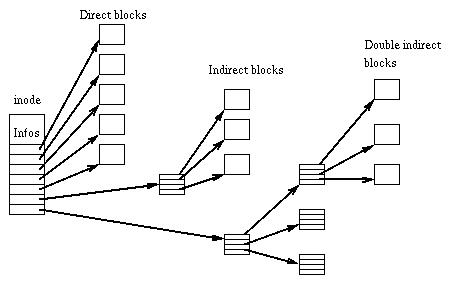
i-węzeł to struktura opisująca plik. Najważniejszą informacją przechowywaną w i-węźle jest położenie treści opisywanego pliku.
Pola direct_block_ptr, {singly,doubly,triply}_indirect_block_ptr przechowują numery bloków (względem początku partycji), w którym znajdują się dane pliku.
struct inode_t {
uint16_t type_and_permissions;
uint16_t user_id;
uint32_t size;
uint32_t last_access_time;
uint32_t creation_time;
uint32_t last_modification_time;
uint32_t deletion_time;
uint16_t group_id;
uint16_t hard_links_count;
uint32_t disk_sectors_used;
uint32_t flags;
uint32_t os_specific_value;
uint32_t direct_block_ptr[12];
uint32_t singly_indirect_block_ptr;
uint32_t doubly_indirect_block_ptr;
uint32_t triply_indirect_block_ptr;
uint32_t generation_number;
uint32_t reserved[2];
uint32_t fragment_address;
uint32_t os_specific_value_2;
}
Wskaźniki pośrednie wskazują na blok zawierający liste bloków danych (lub kolejnych list w przypadku wskaźników podwójnie lub potrójnie pośrednich).
Praktyka
Zakładam, że dysponujemy funkcją
void read_block(uint32_t block_n, void* dst);
realizującą odczyt pojedyńczego bloku o wskazanym numerze.
Odnalezienie konkretnego i-węzła
Jako, że tablica i-węzłów jest rozdzielona między wszystkie grupy bloków, najpierw musimy obliczyć, w której grupie znajduje się interesujący nas i-węzeł. Musimy także pamiętać, że i-węzły numerujemy od 1! Robimy to następującym wyrażeniem:
block_group = (inode_n - 1) / INODES_PER_GROUP
Musimy także znać indeks i-węzła względem tej grupy bloków:
index_in_block_group = (inode_n - 1) % INODES_PER_GROUP
Teraz pozostaje nam policzyć, który blok tablicy musimy odczytać:
block_index = (index_in_block_group * INODE_SIZE) / BLOCK_SIZE
A także indeks naszego i-węzła wewnątrz tego bloku:
index_in_block = (inode_n - 1) % (BLOCK_SIZE / INODE_SIZE)
Mając te wszystkie dane odczytanie i-węzła wygląda następująco:
inode_t get_inode(uint32_t inode_n) {
const uint32_t inodes_per_block = BLOCK_SIZE / INODE_SIZE;
const uint32_t block_group = (inode_n - 1) / INODES_PER_GROUP;
const uint32_t index_in_block_group = (inode_n - 1) % INODES_PER_GROUP;
const uint32_t block_index = (index_in_block_group * INODE_SIZE) / BLOCK_SIZE;
const uint32_t index_in_block = (inode_n - 1) % (inodes_per_block);
inode_t inode_table[inodes_per_block];
read_block(bgdt[block_group].inode_table_ptr + block_index, inode_table);
return inode_table[index_in_block];
}
Odczytanie pliku o znanym numerze i-węzła
Wiemy już, jak odczytać i-węzeł znając jego numer. Teraz wystarczy nam odczytać bloki wskazywane przez ten i-węzeł. Zakładam natomiast, że plik jest na tyle mały, że mieści się w blokach adresowanych bezpośrednio (max rozmiar = 12 bloków >= 12KB).
void read_file(const inode_t& file, void* output_buf, size_t buf_size) {
const size_t& fsize = file.size;
if (fsize > BLOCK_SIZE * 12)
// Plik nie mieści się wewnątrz bezpośrednio adresowanych bloków
throw std::exception();
if (fsize > buf_size)
// Bufor jest mniejszy od pliku
throw std::exception();
int whole_blocks = fsize / BLOCK_SIZE;
int remainder = fsize % BLOCK_SIZE;
// Odczyt w całości zapełnionych bloków
for (int i = 0; i<whole_blocks; ++i) {
read_block(file.direct_block_ptr[i], output_buf+i*BLOCK_SIZE);
}
// Odczyt ostatniego bloku, który nie jest w całości zapełniony
char tmp_buf[BLOCK_SIZE];
read_block(file.direct_block_ptr[whole_blocks], tmp_buf);
memcpy(output_buf + whole_blocks*BLOCK_SIZE, tmp_buf, remainder);
}